SuperDuper! for Catalina Friday, October 18, 2019
As promised, at the bottom of this post is a link to our Catalina beta.
This post is mostly a just-the-facts-ma'am discussion of changes in Catalina that have affected us and may affect you. Details of our journey may come later, when I'm in a more narrative mood.
This version has been a long time coming, and while we hoped to have a beta during Catalina's development, we really didn't like the stability of Catalina during the process. Many things involving the drive setup were changing and being reworked as the summer wore on.
Rather than put out something that was at the mercy of the underlying system, whose release process we couldn't control or predict, we decided to hold off until the real release. Once that was out, we finalized our testing, and now we're putting the public beta into your waiting arms/hands/drives/computers...whatever metaphor here is appropriate.
Drives are Different
Apple's intention is to hide the details, so it's possible you didn't notice, but in Catalina APFS drives are now quite a bit different than they were before. Let's just do a quick refresher of how we got to where we are now.
Stage 1
macOS started out with pretty "standard" Unix-style protections. Permissions and ownership were used to establish what you could or couldn't do with a file. The "super user" could override those permissions, so while you were normally denied access to "system" files, a little "permission escalation" allowed you to modify anything you wanted.
And, since "you" could modify anything with a little work, so could something that had unkind intent.
Stage 2
In 10.4, Apple added ACLs, which are more fine-grained "Access Control Lists": super detailed permissions for files and folders that can be inherited. Most people aren't aware these exist, but they're super handy.
Stage 3
The next step was adding a special attribute ("com.apple.rootless") that caused the file system driver to "protect" certain files on the drive.
That caused some initial consternation that I documented on this blog, because Apple "overprotected" the system, even when it wasn't the startup drive. Fortunately, before shipping, they fixed that problem, and copying worked as expected.
Stage 4
Next came System Integrity Protection (SIP), which took that concept and extended it to some user files as well. Some areas of the drive couldn't even be viewed, let alone copied, but with certain types of authorization (like Full Disk Access), copying could be done.
Stage 5
And now we're at Stage 5, which is either denial or acceptance. I forget, but basically this is where the entire system has been made read-only, and placed on its own, separate volume.
It doesn't look that way in Finder: everything seems like it was. But behind the scenes, two separate volumes have been created. Your files, and dynamic system files, are on a new "Data" volume. The system is on its own "System" volume. And they're stitched together with "firmlinks", a new, system-only feature that makes two volumes look like one at the directory level.
Make this invisible
Again, Apple has tried to make this invisible, and for the most part, that's what they've done. And we've tried to do the same.
In SuperDuper, you won't notice any changes for the most part. But behind the scenes, we've made a lot of modifications:
- In order to replicate this new volume setup, system backups of APFS volumes must be to APFS formatted volumes. SuperDuper automatically converts any HFS+ destinations to APFS volumes for you (after prompting), so you won't have to do anything manually in most cases.
- Any existing APFS volumes are properly split into these new Data and System volumes. If your backup was previously called "Backup", your files are now on a volume called "Backup - Data". The read-only system volume, which contains Apple's files, is called "Backup". These volumes are now set up in a "volume group". Again, all this is done for you, and we hide the details...but if you see some new volumes, you now know why.
- And because of this, a single copy is really two copies: the system volume (when unmodified) and the data volume (where your stuff resides)
- Those two volumes are further linked together with "firmlinks", which tunnel folders from one volume to the other in a way that should be transparent to the user. But they can't be transparent to us, so we had to figure out how to recreate them on the copy, even though there's no documented API.
- Plus, we've needed to make sure we do the right thing when you copy from a regular volume to something that was previously a volume group, intuiting what you mean to do from your copy method.
- I really could go on and on and on here. It certainly felt endless during the process!
Yeah, no matter how much one might long for turtles, it's hacks all the way down.
Seriously, though, this is the kind of thing that requires an enormous amount of testing—not just tests of the program, but testing during development as well. One "little" change that totaled about 10 lines of code required over 1000 lines of unit tests to verify proper operation. And that's just one internal change.
Except when you can't.
Despite our efforts, the new setup means some adjustments must be made.
- You can't turn an already encrypted APFS volume into a volume group. As such, you'll have to decrypt any existing bootable volumes. Once you've backed up, you can boot to that backup, turn on FileVault, and boot back. Subsequent Smart Updates will maintain the encryption.
That doesn't mean you have to back up critical files to an unencrypted volume. If this is important to you (HIPAA or similar requirements are often quite strict about encryption), create a separate account called, say, Intermediate. Use a SuperDuper copy script to exclude your normal User folder (where the critical data is - for example, /Users/dnanian - see Help > User's Guide for a detailed discussion of Copy Scripts). Then, use that new script in "using" to back up to the unencrypted volume.
Start up from the unencrypted volume and log into Intermediate. Turn on FileVault.
Now, start back up from the regular volume and use "Backup - all files" with "Smart Update" to update the backup. This will add your regular account data, which will remain encrypted, as will subsequent Smart Updates.
Unmounted images are a bit of a problem. We don't know what's "in" the image when it's a file, and so we don't have enough information to warn you before the copy starts.
Because of the reasons listed in Make this Invisible, we may need to convert the image to APFS. Some cases might not work, and some we don't want to do without prompting you.
So, we'll give you an error, after the image has been opened. You can then select your image's "open" volume (not the image file itself), and do the backup, once, like that. We'll warn you normally, do the conversions needed, and make the copy. Subsequent updates that don't require conversions will work normally.
- Because we've had to work all through the summer while everyone else was having fun, support may be crankier than normal. Sorry/not sorry.
Wrapping it up
So that's about it. Things should generally feel "normal" to you, although there will be some prompts for those who have encrypted or HFS+ destinations and a Catalina APFS source. Overall, though, the goal is for it to be relatively painless...and I'm sure you'll get in contact if you feel otherwise.
To get started, download the beta below. Note that you'll automatically get subsequent beta releases, and the final Catalina version when available. Once that final version is released, you'll only get release versions...until you manually install another beta.
Thanks for your patience, and we look forward to your (hopefully positive) feedback.
Download SuperDuper! 3.3 Beta 1 (v119.2)
Hey folks. Sorry for the relative silence here. We've been working during the summer on a Catalina update, and unfortunately we're just not quite ready for a general update. But we're close!
Catalina introduces some significant changes to the way a startup drive works, and while we've solved the various issues involved in making the backup process as transparent as possible, it's taken a lot of slow, careful work to get the testing done.
As you might expect, the "new way" Catalina splits your drive into two parts makes things more complicated. The details are hidden from you by Apple for the most part, but SuperDuper has to know, and handle, all the various tricky cases that arise from that split (not to mention the technical details of tying the volumes together, which we figured out early in the summer).
There are stories to tell--our initial intention was to take a different approach than the one we ended up taking--but those will have to wait for when I've got a bit more time.
That said, the GM version was just released on October 3rd, the final version was released today, we've got a beta almost ready to go, and I'll be posting it to the blog as soon as it's passed our internal testing.
That beta works great for most users, but will have some limitations around images: we're probably not going to work with APFS image destinations in the beta when selected as files, if the source is a volume group.
There are also some caveats regarding encrypted destinations: basically, we can't form a "volume group" from a destination that's already encrypted, so you'll have to unencrypt encrypted destinations, copy to them, then boot from them and turn on FileVault.
More soon; thanks for your patience, and thanks for using SuperDuper!
Unrelated Stuff I Like Friday, August 09, 2019
As we plug along with our Catalina changes, I thought I might write a quick post talking about some other stuff I'm enjoying right now. Because, hey, why not.
Coffee Related
Software Development and Coffee go together like Chocolate and My Mouth. And so, a lot of it is consumed around these parts.
I would never claim to be an expert in these things, but I've really been enjoying the Decent Espresso DE1PRO espresso machine. It doesn't just give me a way to brew espresso—many machines can do that—but it gives me the information I need to get better at it, and the capability to make the kind of adjustments needed to do so consistently.
It's a pretty remarkable machine. Basically, it's a very "complete" hardware platform (pumps, heaters, valves, pressure monitors, flow meters, etc) that's driven entirely by software. It comes with a tablet that runs the machine's "UI". And you can tap a button to brew an espresso.
But you can also see the exact pressure/flow/temperature curves happening in real-time as the brew happens. And, even more importantly, you can extensively change the behavior of the machine—adding pauses, changes in pressure, temperature, flow, etc—very easily.
You can emulate lever-style brewing. You can do "Slayer" style shots. You can do simple E61-style shots. The possibilities are endless.
And all of this happens in a machine that's much smaller than any other full capability espresso machine I've ever seen.
And that's not even going into the super helpful and friendly owner forums.
I've spent at least eight months with mine, which I preordered years before it shipped, and it's really made a huge difference. Highly recommended, and surprisingly available at Amazon, but also at the Decent Espresso site. There are less expensive models at the Decent site as well: the PRO has longer duty cycle pumps.
Power Related
A few years ago, I purchase a Sense Energy Monitor to see what I could learn about power consumption in our house beyond just "the bill every month".
Sense is a local company that uses machine learning and smart algorithms to identify individual loads by sensing waveform shapes and patterns in your main electrical feed. So it can identify, over time, a lot of the devices that are using power, how much power they're using out of your entire power use, etc. Which, as a problem, is super difficult...and they've done a very good job.
Sense can identify quite a few things, given time, including electric car charging, refrigerator compressors, AC units, sump pumps, resistance heaters, washing machines, dryers, etc. And it's getting better at these things all the time.
But, of course, they know they can't figure out everything on their own. It's easy for us to plug something in, knowing what it is, and wonder "hey, Sense, why can't you tell me that's an iPhone charger", when that tiny 5W load is deep in the noise of the signal.
So what they've done, on top of their "line" sensing, is integrate with "smart plugs" from TP-Link and Belkin. You can identify what's connected to those plugs, and the Sense will find them and integrate that information into its own energy picture. Plus, the additional information helps to train the algorithms needed to detect things automatically.
It's cool stuff. If you go in not expecting miracles ("Waah! It didn't detect my Roomba!"), and you're interested in this kind of thing, it's pretty great.
$299 at Amazon.
Plug Related
Speaking of smart plugs, boy there are a lot of bad products out there.
There seems to be a reference platform that a lot of Chinese-sourced products are using, with a 2.4GHz radio, some basic firmware, and an app framework, and a lot of products lightly customize that and ship.
Belkin
I don't know if that's the case with Belkin, but their products, while somewhat appealing, fall down hard in a pretty basic case: if there's any sort of power failure, the plug doesn't remember its state, and comes up off.
Given the plug can remember many other things, including its WiFi SSID and password, you'd think it could remember the state the plug was in, but, no.
That behavior along makes it unacceptable.
Not Recommended - no link for you, Belkin.
TP-Link
TP-Link has two products in its Kasa line that do power monitoring: the single socket HS110 and the 6-outlet HS300 power strip.
Both work fine, although the HS110 mostly covers up the 2nd outlet in a wall outlet, and that makes things inconvenient. The HS300 is a better product with a better design. All six outlets are separately controllable and each measures power as well. As a bonus, there are three 5V USB charger ports.
Both properly maintain the status of plugs across a power outage.
I've used both of these successfully in conjunction with the Sense. Standalone, the software is meh-to-OK for most things. It's fine.
There's support for Alexa and Google Home but not HomeKit (the Homebridge plugin only seems to support the HS100).
Highly Recommended for Sense users (especially the HS300); Recommended with caveats for standalone users.
Currant
The Currant smart plug is so much better than any of the other choices in most ways, it's kind of remarkable.
Unlike most other smart plugs, the Currant has two sockets, accessible from the side. It works in either horizontal or vertical orientations, with either side up (the plug can be swapped), and it's got a position sensor inside, so its app can unambiguously tell you which plug is left/right/top/bottom.
The plug itself is attractive and well built. The software is great, and if it's built on the same platform as the others, they've gone well beyond everyone else in terms of customizing their solution.
Plugs are quickly added to your network and the app. New plugs are found almost instantaneously, and announced on the home screen.
Plugs can be named easily, associated with icons and rooms, and the power measurements involved constantly update and are accurate.
Their software automatically recognizes usage patterns and suggests schedules that can be implemented to save energy.
You can even tell them what your power supplier is, and they'll automatically look up current energy costs and integrate that into the display.
There's support, again, for Alexa and Google Home but not HomeKit, and there's no Homebridge plugin. A future version looks to be coming that's a regular wall outlet with the same capabilities.
Finally, as of right now, there isn't (sniff) any support for the plugs in the Sense system.
All that said, these come Highly Recommended for standalone users...and I'd even recommend them for Sense users who don't need these particular loads integrated into the app. They're still measured, of course...they're just not broken out unless recognized normally via Sense's load sensing algorithms.
Here's hoping the Sense folks add support.
The WiFi versions of these plugs were initially expensive at $59.99. However, as of this posting, they're half price at $29.99. Available at Amazon.
Executive Summary: Internally, SuperDuper! can now make bootable copies of "live" Catalina volumes in all three released Beta versions of macOS 10.15. While much work still needs to be done to make things ready for external use, no obstacles are blocking us from pursuing at least one "definitely works" path.
Right up front, allow me to understate something: booting macOS is definitely not getting simpler.
When things change, as they have in Catalina, I've got to delve into what's going on using a combination of on-disk evidence, boot-time kernel logging, and trial-and-error.
When things fail, there's no persistent evidence, so I also spend a lot of time taking pictures of a rapidly scrolling "verbose boot" screen, watching what the kernel is shouting before it fails the boot and shuts down.
A lot of it is kind of tedious work, and there aren't any CSI-style glass panels and black lights to make it look more exciting and cinematic. It's just a bunch of screens and drives and cups of coffee and notes. It looks a bit like a conspiracy theory evidence board. With a crazy-looking person doing the same thing, with minor modifications, over and over again, usually to failure.
Oh-No-Dependent
But, sometimes, to success! And we're now at the point where we have a definite path forward that isn't gated on things we can't control.
That latter issue is a big deal in this business.
When there are bugs or limitations in frameworks or tools or whatever that can't be worked around, it reflects poorly on the product that depends on them. And so we've endeavored to do as much ourselves as we can, to ensure we're not overly coupled to things that have proven to be problematic.
For example, in a previous post, I mentioned how our sparse file handling is much faster than what's built into the system (copyfile) and a typical naïve, cross-platform implementation (rsync). Had we been dependent on either, it would have been much harder to improve the speed as much as we did.
But since we wrote and use our own copy engine, we were able to extensively optimize it without waiting for system-level improvements.
Of course, that has its own potential downsides (copyfile, an Apple API, should handle any OS-level changes needed, but has proven over the years to be buggy, slow, etc), so a careful balance needs to be maintained between dependence and independence. Being more independent means you have to track changes carefully and update when necessary. Being more dependent means you may be broken by factors outside your control...forcing you to rewrite things to be more independent.
Tradeoffs. Whee.
Doing the Right Thing
Last post, I mentioned that we had considered putting in "quick-'n-dirty" Catalina support to try to have something, given the public beta was imminent.
That was going to basically "combine" the two volumes—System and Data—into one, recreating the "old" structure. It was bootable, and "worked", but the problem was with restoration: if you wanted to restore more than just a few files, you would have had to clean install Catalina and migrate from the backup.
That is, basically, what you have to do to restore from Time Machine (it's handled for you), so we decided it just wasn't offering enough of a benefit beyond what Apple was going to provide, especially since we just wouldn't have enough time to test against all the different scenarios involved.
So, we decided to take the "hit" of not having something available, rather than have something "not good enough".
I know that's frustrating to users out there using these early Catalina builds, but, frankly, if you're jumping on early betas you know what you're in for. We're working hard to have a real solution available as soon as we can.
3.2.5's Continued Success
The new public version of SuperDuper continues to perform really well. The biggest issue we've seen is that some people are running through the "old" purchase process on an old version of SuperDuper, rather than installing 3.2.5 and purchasing in the app or the web site. But I can fix that up as soon as they contact me at support.
So, if you have a problem, contact me at support...
Forecast: Brighter Days Ahead
We continue to work to produce a version of SuperDuper! that's usable by "regular users", with a quality level appropriate for a Beta version. Good progress is being made, the path is clear, and now it's just a matter of writing, debugging and testing the rest of the code.
That's not a small task, of course. But it could be a lot worse!
More as there's anything interesting to add...
Up and down the coast Tuesday, July 02, 2019
Another June has come (and gone), and with it the promise of a new, improved version of macOS. In this case, macOS 10.15: Catalina. Sounds so refreshing, doesn't it? Cool breezes, beautiful sunsets, pristine beaches along an endless coast.
But no matter what the imagery looks like, it's a time when I sit at Shirt Pocket HQ, braced for the inevitable news that it's going to be a long, hot summer. In my office. Drinking a lot of coffee.
Thus, in preparation for a lot of upcoming changes, we released v3.2.5 of SuperDuper to wrap up the work we did over the past few months. That release went great, and so it's time to recap previous OS releases and look to the future.
High Sierra
Back in 2017, the announcement of APFS was a big one: it meant re-engineering a lot of SuperDuper! to support the new (and barely documented) file system, along with its new capabilities and requirements. It meant months of investigation and implementation.
A difficult trek for us, but in the end, it meant a pretty painless transition for users, and with it came new features like Snapshots.
But it took us quite a while before we had a version that could be used externally.
Mojave
macOS 10.14 brought its own challenges, and new restrictions on what data could and couldn't be accessed, how scripting could and couldn't work, etc. This required even more reengineering, and another busy summer, despite the fact that Mojave was intended as a Snow Leopard-like "cleanup" release.
But, again, with that work came new capabilities, including better scheduling, smoother operation, command-line support, Smart Wake and Smart Delete.
Unlike the Mojave version, though, we were able to release something that would work well enough pretty early in the Beta cycle.
Catalina
Before going into this, let me state what should be obvious: if you're not specifically writing software that requires you to install Catalina, you shouldn't install the Catalina beta. Really. Let those of us who have to do this take the arrows. Once everything looks great, then you can come rushing in, looking all smart and heroic, and win the day.
Right now, for "regular users", there's no winning. It's all just blood and pain.
Catalina presents more challenges. Not only is the execution environment tightened further, with new requirements and restrictions, but the whole way the startup drive works has been significantly changed.
And I mean very significantly.
In essence, the startup volume is now comprised of two different volumes. The first is the "System" volume, which is what you start up from. That volume is now entirely read-only. Nobody can write to it, except the system, and even then, only when doing OS installs or updates. Users can't write to it. Applications can't write to it.
Basically, think of it as a Catalina CD-ROM you boot from. But, like, faster. And it can be updated. And it's not shiny.
OK, so maybe that's a bad analogy, but you get the idea.
Accompanying that is a new "Data" volume. That's where "your" stuff is. It's read/write. But it's also not visible: the System volume and the Data volume are combined into a new low-level structure called a "Volume Group".
The System volume "points to" the Data volume in this group using another new feature: firmlinks. And as with writing to the System volume itself, only Apple can create firmlinks. (Well, they're "reserved to the system". Plus, additional "synthetic" firmlinks are coming for network resources, but the details of those aren't out yet.)
This sounds complicated (and it is), but it's all supposed to be completely invisible to the user. You might not even notice if you're not the kind of person who looks closely at Disk Utility. (Then again, you're reading this, so you'd probably notice.)
That said, it's not (and can't be) invisible to SuperDuper. This new arrangement presents those of us who are creating bootable backups with—and I'll employ my mildest language here; the forehead-shaped dents in my desk tell a different story—something of a challenge: we can't write to a system volume (again, it's read-only) and we can't create firmlinks.
So...how are we going to create backups? How are we going to restore them?
Yeah, right around here during the announcement is where I might have peed myself a little.
Fetch My Deerstalker Hat! And Some Dry Pants!
Rather than draw this out further, after that initial panic (which always happens during WWDC, so I make sure I've got a ready change of clothes), I've done quite a lot of investigative work, delving into the new, mostly undocumented capabilities, many new APFS volume roles, how they all interact, and I've developed an approach that should work. It does, as they say, in "the lab".
That approach will require, once again, a huge number of changes on our end. These changes will be as extensive as the ones we had to make when APFS was introduced, if not more so. We have to take a quite different approach to copying, make understandable errors appear when the underlying system APIs provide no details, and we have to depend on a bunch of new, unfinished, un-and-under-documented things to make any of this work at all.
It also definitely means you won't be able to back up APFS to an HFS+ volume in 10.15. It's APFS turtles all the way down from here on out, folks, so if you haven't moved your backup volumes to APFS yet, plan to do so once you install Catalina.
But What Does That Mean For MEEEEE?
It's always about you, isn't it...Stuart. (Yes, you, Stuart. Who did you think I was talking about?)
Our goal, of course, is to make all of this new stuff invisible, or as close to invisible as possible. So, when you upgrade to Catalina, and you want to back it up with SuperDuper, it'll basically work the way it always has.
During development, though, this means Catalina is going to be more like Mojave. It'll be a while until we have something to share that you can use. During 3.2.5's development, we tried to come up with something "quick and (not too) dirty" that would do the job well enough to give people with the early betas some coverage, and it just couldn't be done to a quality level we were happy with.
We don't want to release something that we aren't confident will work reliably, even if there are some limitations. That'd be bad for you, and bad for us. So for now, if you're on an early Catalina beta, use Time Machine (and cross your fingers/sacrifice a chocolate bunny/pray to the backup gods).
So far, while we've validated the general approach, we've run into a lot of problems around the edges. Catalina's file system and tools are rife with bugs. Every time we head down one path, we're confronted with unexpected behavior, undocumented tools, crashes and failures. While we're reporting things to Apple, we're two betas in now, and it's not getting better.
Yet. Which is important, as it's still early days. No doubt Apple's exhausted engineers are barely recovered from the push to get stuff ready for WWDC (working to hard dates is never fun; we've all been there), and typically Developer Beta 2 is just "the stuff that we couldn't get done for WWDC that we wanted in Developer Beta 1". And—hey!—Developer Beta 3 just dropped, so who knows!
Anyway, we're forging ahead, confident in our approach. When we have something we will, as always, post it to the blog...and I'll be sharing any interesting trials and tribulations along the way.
When I'm done banging my head against my desk, at least.

You'd think, given I've written everything here, I'd learn to pay attention to what I've said in the past.
Let me explain. In v3.2.4, we started getting occasional reports of scheduled copies running more than once. Which seemed kind of crazy, because, well, our little time-based backup agent—sdbackupbytime—only runs once a minute, and I'd reviewed the code so many times. There was no chance of a logic error: it was only going to run these puppies one time.
But it was, sometimes, regardless. And one of the things I had to change to complete Smart Wake was to loop to stay active when there was a backup coming in the next minute. But the code was definitely right. Could that have caused this to happen?
(Spoiler alert after many code reviews, hand simulations and debugger step-throughs: NO.)
So if that code was right, why the heck were some users getting occasional multiple runs? And why wasn't it happening to us here at Shirt Pocket HQ?
Of course, anyone who reported any of these problems received an intermediate build that fixed them all. We didn't rush out a new update because the side effect was more copies rather than fewer.
Secondary Effects
Well, one thing we did in 3.2.4 was change what SuperDuper does when it starts.
Previously, in order to work around problems with Clean My Mac (which, for some reason, incorrectly disables our scheduling when a cleanup pass is run, much to my frustration), we changed SuperDuper to reload our LaunchAgents when it starts, in order to self-repair.
This worked fine, except when sdbackupbytime was waiting a minute to run another backup, or when sdbackuponmount was processing multiple drives. In that case, it could potentially kill the process waiting to complete its operation. So, in v3.2.4, we check to see if the version is different, and only perform the reload if the agent was updated.
The known problem with this is that it wouldn't fix Clean My Mac's disabling until the next update. But it also had a secondary effect: these occasional multiple runs. But why?
Well, believe it or not, it's because of ThrottleInterval. Again.
Readers may recall that launchd's ThrottleInterval doesn't really control how often a job might launch, "throttling" it to only once every n seconds. It actually forces a task to relaunch if it doesn't run for at least n seconds.
It does this even if a task succeeds, exits normally, and is set up to run, say, every minute.
sdbackupbytime is a pretty efficient little program, and takes but a fraction of a second to do what it needs to do. When it's done, it exits normally. But if it took less than 10 seconds to run, the system (sometimes) starts it again...and since it's in the same minute, it would run the same schedule a second time.
The previous behavior of SuperDuper masked this operation, because when it launched it killed the agent that had been re-launched: a secondary, unexpected effect. So the problem didn't show up until we stopped doing that.
And I didn't expect ThrottleInterval to apply to time-based agents, because you can set things to run down to every second, so why would it re-launch an agent that was going to have itself launched every minute? (It's not that I can't come up with reasons, it's just that those reasons are covered by other keys, like KeepAlive.)
Anyway, I changed sdbackupbytime to pointlessly sleep up to ThrottleInterval seconds if it was going to exit "too quickly", and the problem was solved...by doing something dumb.
Hey, you do what you have to do, you know? (And sometimes what you have to do is pay attention to your own damn posts.)
Queue'd
Another big thing we did was rework our AppleScript "queue" management to improve it. Which we did.
But we also broke something.
Basically, the queue maintains a semaphore that only allows one client at a time through to run copies using AppleScript. And we remove that client from the queue when its process exits.
The other thing we do is postpone quit when there are clients in the queue, to make sure it doesn't quit out from under someone who's waiting to take control.
In 3.2.4, we started getting reports that the "Shutdown on successful completion" command wasn't working, because SuperDuper wasn't quitting.
Basically, the process sending the Quit command was queued as a task trying to control us, and it never quit...so we deferred the quit until the queue drained, which never happened.
We fixed this and a few similar cases (people using keyboard managers or other things).
Leaving Things Out
As you might know, APFS supports "sparse files" which are, basically, files where "unwritten" data takes up no space on a drive. So, you might have a file that was preallocated with a size of 200GB, but if you only wrote to the first 1MB, it would only take up 1MB on the drive.
These types of files aren't used a lot, but they are used by Docker and VirtualBox, and we noticed that Docker and VirtualBox files were taking much longer to copy than we were comfortable with.
Our sparse file handling tried to copy a sparse file in a way that ensured it was taking a minimal amount of space. That meant we scanned every read block for zeros, and didn't write the sections of files that were 0 by seeking ahead from that point, and writing the non-zero part of the block.
The problem with this is that it takes a lot of time to scan every block. On top of that, there were some unusual situations where the OS would do...weird things...with certain types of seek operations, especially at the end of a file.
So, in 3.2.5, we've changed this so that rather than write a file "optimally", maximizing the number of holes, we write it "accurately". That is, we exactly replicate the sparse structure on the source. This speeds things up tremendously. For example, with a typical sparse docker image, the OS's low-level copyfile function takes 13 minutes to copy with full fidelity, rsync takes 3 minutes and doesn't provide full fidelity, whereas SuperDuper 3.2.5 takes 53 seconds and exactly replicates the source.
That's a win.
Don't Go Away Mad...
In Mojave 10.14.4 or so, we starting getting reports of an error unmounting the snapshot, after which the copy would fail.
I researched the situation, and in this unusual case, we'd ask the OS to eject the volume, it would say it wasn't able to, then we'd ask again (six times), and we'd get an error each time...because it was already unmounted.
So, it would fail to unmount something that it would then unmount. (Winning!)
That's been worked around in this update. (Actual winning!)
Improving the Terrible
As you've seen, Apple's process for granting Full Disk Access is awful. There's almost no guidance in the window—it's like they made it intentionally terrible (I think they did, to discourage people from doing it).
We'd hoped that they'd improve it, and while some small improvements have been made, it hasn't been enough. So, thanks to some work done and generously shared by Media Atelier, we now provide instructions and a draggable application proxy, overlaid on the original window. It's much, much better now.
Thanks again and a tip of the pocket to Pierre Bernard of Houdah Software and Stefan Fuerst of Media Atelier!
eSellerate Shutdown
Our long-time e-commerce provider, eSellerate, is shutting down as of 6/30. So, we had to move to a new "store".
After a long investigation, we've decided to move to Paddle, which—in our opinion—provides the best user experience of all the ones we tried.
Our new purchase process allows payment through more methods, including Apple Pay, and is simpler than before. And we've implemented a special URL scheme so your registration details can now be entered into SuperDuper from the receipt with a single click, which is cool, convenient, and helps to ensure they're correct.
Accomplishing this required quite a bit of additional engineering, including moving to a new serial number system, since eSellerate's was going away. We investigated a number of the existing solutions, and really didn't want to have the gigantically long keys they generated. So we developed our own.
We hope you like the new purchase process: thanks to the folks at Rogue Amoeba, Red Sweater Software, Bare Bones Software and Stand Alone—not to mention Thru-Hiker—for advice, examples and testing.
Note that this means versions of SuperDuper! older than 3.2.5 will not work with the new serial numbers (old serial numbers still work with the new SuperDuper). If you have a new serial number and you need to use it with an old version, please contact support.
(Note that this also means netTunes and launchTunes are no longer available for purchase. They'll be missed, by me at least.)
Various and Sundry
I also spent some time improving Smart Delete in this version; it now looks for files that have shrunk as candidates for pre-moval, and if it can't find any space, but we're writing to an APFS volume, I proactively thin any snapshots to free up space on the container.
All that means even fewer out of space errors. Hooray!
We also significantly improved our animations (which got weird during 10.13) by moving our custom animation code to Core Animation (wrapping ourselves in 2007's warm embrace) and fixed our most longstanding-but-surprisingly-hard-to-fix "stupid" bug: you can now tab between the fields in the Register... window. So, if you had long odds on that, contact your bookie: it's going to pay off big.
With a Bow
So there you go - the update is now available in-app, and of course has been released on the Shirt Pocket site. Download away!
On March 7, 2019, I unfortunately lost my Dad (which is why support has been a bit slow recently). I thought I'd post my eulogy for him here, as delivered, should anyone care. He was a good man, and will be missed.
Good morning, everyone. I’m David Nanian, up here representing my Mom and my brothers, John and Paul. Thanks so much for coming.
All of us here knew my Dad and were, without question, better off for it.
He’d greet you, friend or soon-to-be-friend, with a smile and a twinkle in his eye because, well, that was the kind of person he was. He exuded warmth and kindness. It was obvious as soon as you saw him.
And so we’re here today to celebrate him. To celebrate his achievements, certainly, because he was a great doctor. But also to celebrate his … his goodness. He was, truly, a good man.
It took my brothers and me a while to realize this. Like most kids, we went through the typical phases as we matured, where Dad went from a benevolent, God-like presence when we were kids, to a capricious one when we were teens… but that was mostly about us, not him.
Dad worked hard. Mom was a constant, grounding presence at home, but Dad’s typical day started early, and he usually wasn’t home until 8.
Dad’s sunny optimism and caring nature helped to heal many patients, but it took a lot out of him, and when he did come home, he was bone tired. After eating he’d usually fall asleep in his chair in front of the TV—only to awaken if we tried to change the channel. My brothers and I even tried slowly ramping down the volume, switching the channel, and then ramping it back up…it would sometimes work, but when it didn’t he’d wake up with a start, hopping mad.
He’d work hard, and would cover other doctors’ shifts on holidays, so that he’d have larger blocks of time for vacation with the family. And when that time came, he was a sometimes exhausting whirlwind of energy, trying to cram in eleven-something months of missed family time into a few focused weeks…something he’d be looking forward to with anticipation, while we were a bit more apprehensive.
Where would the new “shortcut” on the ride to Kennebunkport take us this time? Was Noonan’s Lobster Hut 3 minutes or 3 hours away?
It was always an adventure.
When I was in my teens, Dad gave me a job mounting cardiograms. I think all three of us did this work at one point or another. It gave us a chance, not just to earn a little money to fritter away on comics or whatever, but also to see Dad at work. There, we could see how admired he was by his colleagues, staff and patients, and I began to see him not just as the “Dad” presence he was during our childhood, but as a real person.
During this time (and even today: Mom recently had this happen in an elevator when Dad was in the hospital), people would constantly stop me in the hallways and tunnels of Rhode Island Hospital as I was doing an errand for him—typically, getting him a Snickers bar—and they’d tell me what a great person he was. How he’d helped take care of their parent, or had a terrific sense of humor, or how quick he was with a kind word or helpful comment.
Later, during my college years, my friends—after meeting my parents—would constantly tell me how awesome my Mom and Dad were. How normal. How much they wish their own parents were like mine.
Which was weird at the time, but, I mean, they were right. I have great parents. I had a great Dad.
So I wanted to tell three little stories about why that was, from when I was old enough to understand.
—
Dad’s enthusiasm and optimism were positive traits, but they occasionally got him into some trouble.
I’d recently graduated from College, and that winter our family went on a ski vacation to Val d’Isere.
Dad was absolutely dying to try Raclette—which, if you don’t know, is a dish popular in that region where a wheel of cheese is heated at the table and scraped onto plates that have potatoes, pickles, vegetables, meats. It’s delicious, but quite filling.
So, we went to a small, family restaurant, and they brought out the various parts of the dish—there were quite a few plates of the traditional items—along with a big half-wheel of cheese and its heating machine.
Now, normally, that 8 pound chunk would last the restaurant a long time. It seemed super clear to the rest of us, just from the size, that there was no way it was “our cheese”. But Dad was absolutely convinced we were supposed to finish the whole thing. To do otherwise was to insult our hosts.
And so, to the obvious horror of the owners watching from the kitchen, Dad—in an attempt to not be ungrateful, to not be the ugly American—tried to finish the cheese.
The rest of us tapped out, but more plates came as Dad—never one to give up—desperately tried to do the right thing.
In the end, much to his chagrin, and the owner’s obvious relief, he couldn’t. Dad apologized for not being able to finish (I think, this is where my brothers and I snarkily told him to tell the waitress “Je suis un gros homme”), and they replied with something along the lines of “That’s quite all right”—but Dad’s attempt to conquer the wheel with such gusto, for the right-yet-wrong reason, even though we could all see the effort was doomed, was human and funny and endearing.
—
He loved to sail. We had a small boat, a 22-foot Sea Sprite named Systolee, and we’d sail it for fun, but Dad also participated in the East Greenwich Yacht Club’s Sea Sprite racing series.
Season after season, we’d come in last, or second to last, but he had a great time doing it, holding the tiller while wearing his floppy hat, telling us—the crew—to do this or that with the sails.
I’d had some success one summer racing Sunfish, and the next year, Dad let me skipper the Systolee in the race series, with him and Mom as crew.
I didn’t make it easy. It was important to be aggressive, especially at the start of a race, and both Mom and Dad would follow my various orders nervously as we came within inches of other boats, trying to hit the line exactly as the starting gun went off.
But he let me do it. He watched me as, one day, I climbed the mast of the pitching boat in the middle of a race in a stormy bay to retrieve a lost halyard—admittedly a crazy thing to do—despite his fear of heights, since he knew abandoning the race would be end up being my failure, not his.
And that season, we came in second overall. But more than the trophy and the opportunity, he gave me the gift of trusting me, and treating me as an equal, week after week. Of allowing me to be better than him at something he loved.
—
Finally, Dad had some health challenges later in life. At one point, he came down with some weird peripheral neuropathy that was incorrectly diagnosed as Lou Gehrig’s Disease.
Fortunately, more testing in Boston showed that it wasn’t ALS, but some sort of neuropathy, and while it didn’t take his life, it did take away much of his balance, and with that, it took away skiing.
Dad loved skiing—and missed a real career writing overly positive ski condition reports for snow-challenged Eastern ski areas—and from my earliest days skiing with him it was clear he wanted nothing more than to be the oldest skier on the slopes, teaching his grandkids to love it the way he did.
Possibly, he just wanted to be old enough to be able to ski for free. He did love a bargain.
Anyway.
He didn’t let his neuropathy hold him back—of course he didn’t—and started traveling with Mom all over the world, and they’d regale us with the stories of the places they’d been, the classes they took…the number of bridge hands they won (or lost). He especially loved the safari they went on in Tanzania, and brought back many great pictures of the landscape and wildlife they’d seen.
He loved learning new things, and had more time to read, to make rum raisin ice cream (the secret, he’d tell us, is to soak the raisins in the rum…overnight!), and to enjoy the Cape with Mom. He was able to relax and play with his grandkids, and it was great to see him entertain my friends’ kids as well.
When he got his cancer diagnosis, he took the train to Boston to meet with his doctors, learned about Uber and Lyft, and was just fiercely determined, independent and optimistic. To illustrate his attitude, he just had a cataract repaired and he had the other one scheduled to be fixed in a few weeks.
During this time, the doctors and staff at Mass General would tell us that he was their hero. Not, I think, for facing his disease with courage and determination, although he did do that. But because he was 88, 89, 90, and full of life, of humor, and of love.
And of course, we all saw that too. Because he was our hero.
—
The last time I was with Dad, just a few weeks ago, he was clearly feeling poorly, and while he kept a brave and cheerful facade he also, with a voice tinged with regret, wanted to make sure that I knew how proud he was of John, and Paul, and me. And how he felt badly that he never told us that enough…because he didn’t want to spoil us.
You know, books and movies through the centuries constantly depict sons and daughters desperate to get the slightest bit of approval from their dads.
For us, though, he took clear delight in what we all did. He looked with admiration and approval at John’s beautiful photography, Paul’s Peace Corps service and ultralight outdoor kit business built from his travel and experience hiking the Appalachian trail, my crazy computer stuff.
And so I told him, as clearly as I could, that it was never in doubt.
Of course we knew.
Just as each and every one of you know how much he cared for you. Whether you were part of his family, a patient, or a friend, he made it clear. He was truly happy to know you. You were truly loved.
And now he’s gone, and the world is a little bit darker because of it. But we all have, within us, a memory of him. A memory of his kindness, his boundless optimism, his love, his zest for life.
And with that in our hearts, we can look out, perhaps at the snow outside: dirty brown, with bare patches, rocks, ice…ice covered rocks. You know, if you’re an Eastern skier: it’s “machine loosened frozen granular”.
Imagine him there, with his arm around your shoulders, and a big smile on his face, and see it the way he’d make you see it.
See that the snow condition’s fantastic. It’s always fantastic. Life is terrific. Every day.
Remember that, greet the day with a mischievous smile and an open heart, and think of him.
…But Sometimes You Need UI Monday, November 12, 2018
As much as I want to keep SuperDuper!'s UI as spare as possible, there are times when there's no way around adding things.
For years, I've been trying to come up with a clever, transparent way of dealing with missing drives. There's obvious tension between the reasons this can happen:
- A user is rotating drives, and wants two schedules, one for each drive
- When away from the desktop, the user may not have the backup drive available
- A drive is actually unavailable due to failure
- A drive is unavailable because it wasn't plugged in
While the first two cases are "I meant to do that", the latter two are not. But unfortunately, there's insufficient context to be able to determine which case we're in.
Getting to "Yes"
That didn't stop me from trying to derive the context:
I could look at all the schedules that are there, see whether they were trying to run the same backup to different destinations, and look at when they'd last run... and if the last time was longer than a certain amount, I could prompt. (This is the Time Machine method, basically.)
But that still assumes that the user is OK with a silent failure for that period of time...which would leave their data vulnerable with no notification.
I could try to figure out, from context (network name, IP address), what the typical "at rest" configuration is, and ignore the error when the context wasn't typical.
But that makes a lot of assumptions about a "normal" context, and again leaves user data vulnerable. Plus, a laptop moves around a lot: is working on the couch different than at your desk, and how would you really know, in the same domicile? What about taking notes during a meeting?
- How do you know the difference between this and being away from the connection?
- Ditto.
So after spinning my wheels over and over again, the end result was: it's probably not possible. But the user knows what they want. You just have to let them tell you.
And so:
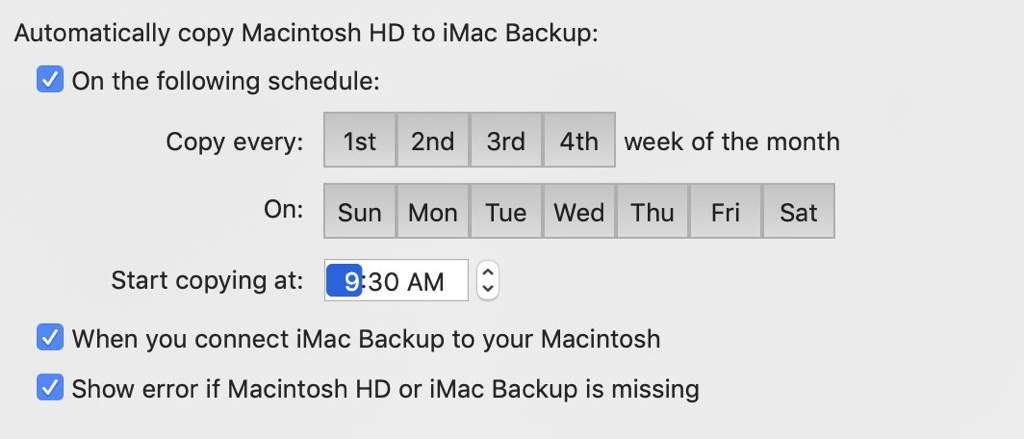
The schedule sheet now lets you indicate you're OK with a drive being missing, and that we shouldn't give an error.
In that case, SuperDuper won't even launch: there'll just be blissful silence.
The default is checked, and you shouldn't uncheck it unless you're sure that's what you want...but now, at least, you can tell SuperDuper what you want, and it'll do it.
And who knows? Maybe in the future we'll also warn you that it's been a while.
Maybe.
He's Dead, Jim
If you're not interested in technical deep-dives, or the details of how SuperDuper does what it does, you can skip to the next section...although you might find this interesting anyway!
In Practices Make Perfect (Backups), I discuss how simpler, more direct backups are inherently more reliable than using images or networks.
That goes for applications as well. The more complex they get, the more chances there are for things to go wrong.
But, as above, sometimes you have no choice. In the case of scheduling, things are broken down into little programs (LaunchAgents) that implement the various parts of the scheduling operation:
sdbackupbytime manages time-based schedulessdbackuponmount handles backups that occur when volumes are connected
Each of those use sdautomatedcopycontroller to manage the copy, and that, in turn, talks to SuperDuper to perform the copy itself.
As discussed previously, sdautomatedcopycontroller talks to SuperDuper via AppleEvents, using a documented API: the same one available to you. (You can even use sdautomatedcopycontroller yourself: see this blog post.)
Frustratingly, we've been seeing occasional errors during automated copies. These were previously timeout errors (-1712), but after working around those, we started seeing the occasional "bad descriptor" errors (-1701) which would result in a skipped scheduled copy.
I've spent most of the last few weeks figuring out what's going on here, running pretty extensive stress tests (with >1600 schedules all fighting to run at once; a crazy case no one would ever run) to try to replicate the issue and—with luck—fix it.
Since sdautomatedcopycontroller talks to SuperDuper, it needs to know when it's running. Otherwise, any attempts to talk to it will fail. Apple's Scripting Bridge facilitates that communication, and the scripted program has an isRunning property you can check to make sure no one quit the application you were talking to.
Well, the first thing I found is this: isRunning has a bug. It will sometimes say "the application isn't running" when it plainly is, especially when a number of external programs are talking to the same application. The Scripting Bridge isn't open source, so I don't know what the bug actually is (not that I especially want to debug Apple's code), but I do know it has one: it looks like it's got a very short timeout on certain events it must be sending.
When that short timeout (way under the 2-minute default event timeout) happens, we would get the -1712 and -1701 errors...and we'd skip the copy, because we were told the application had quit.
To work around that, I'm no longer using isRunning to determine whether SuperDuper is still running. Instead, I observe terminated in NSRunningApplication...which, frankly, is what I thought Scripting Bridge was doing.
That didn't entirely eliminate the problems, but it helped. In addition, I trap the two errors, check to see what they're actually doing, and (when possible) return values that basically have the call run again, which works around additional problems in the Scripting Bridge. With those changes, and some optimizations on the application side (pro tip: even if you already know the pid, creating an NSRunningApplication is quite slow), the problem looks to be completely resolved, even in the case where thousands of instances of sdautomatedcopycontroller are waiting to do their thing while other copies are executing.
Time's Up
Clever readers (Hi, Nathan!) recognized that there was a failure case in Smart Wake. Basically, if the machine fell asleep in the 59 seconds before the scheduled copy time, the copy wouldn't run, because the wake event was canceled.
This was a known-but-unlikely issue that I didn't have time to fix and test before release (we had to rush out version 3.2.3 due to the Summer Time bug). I had time to complete the implementation in this version, so it's fixed in 3.2.4.
And with that, it's your turn:
Download SuperDuper! 3.2.4
The Best UI is No UI Saturday, October 27, 2018
In v3.2.2 of SuperDuper!, I introduced the new Auto Wake feature. It's whole reason for being is to wake the computer when the time comes for a backup to run.
Simple enough. No UI beyond the regular scheduling interface. The whole thing is managed for you.
But What About...?
I expected some pushback but, well, almost none! A total of three users had an issue with the automatic wake, in similar situations.
Basically, these users kept their systems on but their screens off. Rather inelegantly, even when the system is already awake, a wake event always turns the screen on, which would either wake the user in one case, or not turn the screen off again in the other due to other system issues.
It's always something.
Of course, they wanted some sort of "don't wake" option...which I really didn't want to do. Every option, every choice, every button adds cognitive load to a UI, which inevitably confuses users, causes support questions, and degrades the overall experience.
Sometimes, of course, you need a choice: it can't be helped. But if there's any way to solve a problem—even a minor one—without any UI impact, it's almost always the better way to go.
Forget the "almost": it's always the better way to go. Just do the right thing and don't call attention to it.
That's the "magic" part of a program that just feels right.
Proving a Negative
You can't tell a wake event to not wake if the system is already awake, because that's not how wake events work: they're either set or they're not set, and have no conditional element.
And I mentioned above, they're not smart enough to know the system is already awake.
Apple, of course, has its own "dark wake" feature, used by Power Nap. Dark wake, as is suggested by the name, wakes a system without turning on the screen. However, it's not available to 3rd party applications and has task-specific limitations that tease but do not deliver a solution here.
And you can't put up a black screen on wake, or adjust the brightness, because it's too late by the time the wake happens.
So there was no official way to make the wake not wake the screen available to 3rd parties.
In fact, the only way to wake is to not wake at all...but that would require an option. And there was no way I was adding an option. Not. Going. To. Happen.
Smart! Wake!
Somehow, I had to make it smarter. And so, after some working through the various possibilities... announcing... Smart Wake! (Because there's nothing like driving a word like "Smart" into the ground! At least I didn't InterCap.)
For those who are interested, here's how it works:
- Every minute, our regular "time" backup agent looks to see if it has something to do
- Once that's done, it gathers all the various potential schedules and figures out the one that will run next
- It cancels any previous wake event we've created, and sets up a wake event for any event more than one minute into the future
Of course, describing it seems simple: it always is, once you figure it out. Implementing it wasn't hard, because it's built on the work that was already done in 3.2.2 that manages a single wake for all the potential events. Basically, if we are running a minute before the backup is scheduled to run, we assume we're also going to be running a minute later, and cancel any pending wakes for that time. So, if we have an event for 3am, at 2:59am we cancel that wake if we're already running.
That ensures that a system that's already awake will not wake the screen, whereas a system that's sleeping will wake as expected.
Fixes and Improvements
We've also fixed some other things:
- Due to a pretty egregious bug in Sierra's power manager (Radar 45209004 for any Apple Friends out there, although it's only 10.12 and I'm sure 10.12 is not getting fixed now), multiple alarms could be created with the wrong tag.
- Conversion to APFS on Fusion drives can create completely invalid "symlinks to nowhere". We now put a warning in the log and continue.
- Every so often, users were getting timeout errors (-1712) on schedules
- Due to a stupid error regarding Summer Time/Daylight Savings comparisons, sdbackupbytime was using 100% CPU the day before a time change
- General scheduling improvements
That's it. Enjoy!
Download SuperDuper! 3.2.3
